hybrid_dat <- hybrid_sf |>mutate(y = n_pos, n = n_tested)cmp_base <- y ~1+ elevation + ndvi + urban +field(geometry, model = spde)fit_base <-bru(components = cmp_base,family ="binomial",data = hybrid_dat,Ntrials = hybrid_dat$n)summary(fit_base)
inlabru version: 2.13.0.9024
INLA version: 25.12.02
Latent components:
elevation: main = linear(elevation)
ndvi: main = linear(ndvi)
urban: main = linear(urban)
field: main = spde(geometry)
Intercept: main = linear(1)
Observation models:
Model tag: <No tag>
Family: 'binomial'
Data class: 'sf', 'tbl_df', 'tbl', 'data.frame'
Response class: 'numeric'
Predictor: y ~ elevation + ndvi + urban + field + Intercept
Additive/Linear/Rowwise: TRUE/TRUE/TRUE
Used components: effect[elevation, ndvi, urban, field, Intercept], latent[]
Time used:
Pre = 0.99, Running = 2.36, Post = 0.405, Total = 3.75
Fixed effects:
mean sd 0.025quant 0.5quant 0.975quant mode kld
elevation -0.025 0.002 -0.029 -0.025 -0.021 -0.025 0
ndvi 1.470 0.510 0.451 1.474 2.464 1.473 0
urban 0.983 0.132 0.724 0.983 1.243 0.983 0
Intercept 0.706 0.595 -0.449 0.701 1.891 0.701 0
Random effects:
Name Model
field SPDE2 model
Model hyperparameters:
mean sd 0.025quant 0.5quant 0.975quant mode
Range for field 8.07e+04 4.72e+04 2.50e+04 6.94e+04 2.04e+05 5.2e+04
Stdev for field 5.88e-01 1.37e-01 3.59e-01 5.74e-01 8.94e-01 5.5e-01
Marginal log-Likelihood: -430.18
is computed
Posterior summaries for the linear predictor and the fitted values are computed
(Posterior marginals needs also 'control.compute=list(return.marginals.predictor=TRUE)')
Part 2 — ML systematic component (explain covariates flexibly)
Why ML?
Classical linear terms assume:
\[\eta(s) = \beta_0 + \beta_1 \text{ndvi} + \beta_2 \text{elev} + \beta_3 \text{urban}\] But in practice:
nonlinear responses (e.g., risk peaks at intermediate NDVI)
interactions (e.g., urban × elevation)
ML models are good at learning this.
Target for ML
We want ML to model the systematic component. There are two common choices: A) ML on prevalence and B) ML on the transformed prevalence (empirical logit transformation). We will use B in this tutorial. There are many other transformations that can be considered. Hence, we can create a pseudo-response: \[\tilde{\eta}_i = \text{log}\left(\frac{y_i + 0.5}{n_i -y_i +0.5}\right)\]
For the hybrid pipeline, either is fine. We proceed with RF, but XGBoost works similarly.
Part 3 — Spatial residual modelling of ML residuals
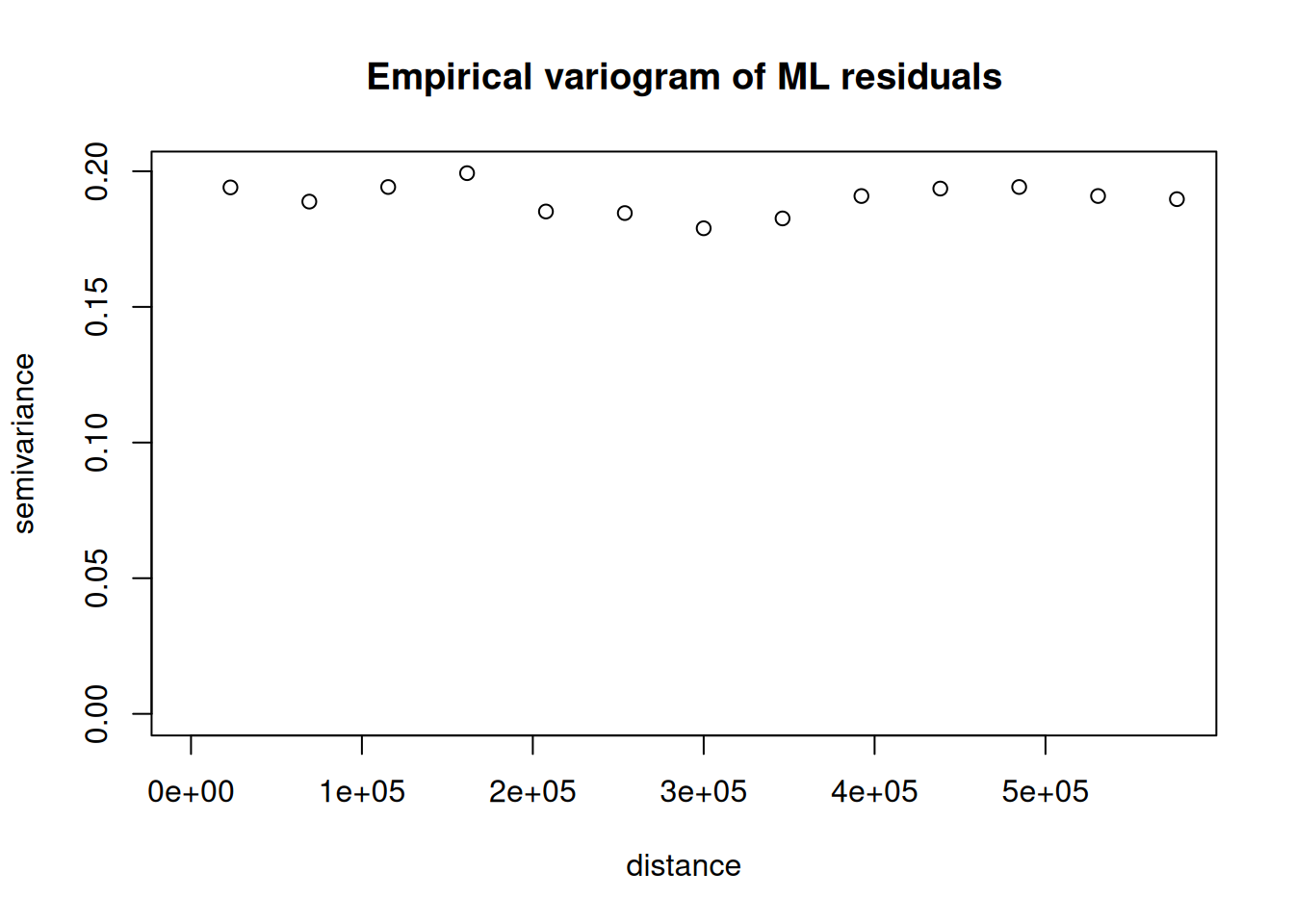
The key diagnostic question
After ML, compute residuals: \[r_i = \tilde{\eta}_i - \hat{m}(x_i),\] where \(\hat{m}\) is the ML prediction. If \(r_i\) shows evidence of spatial correlation, then ML has a missing spatial structure. We then model: \[r_i = S(s_i) + \epsilon_i.\]
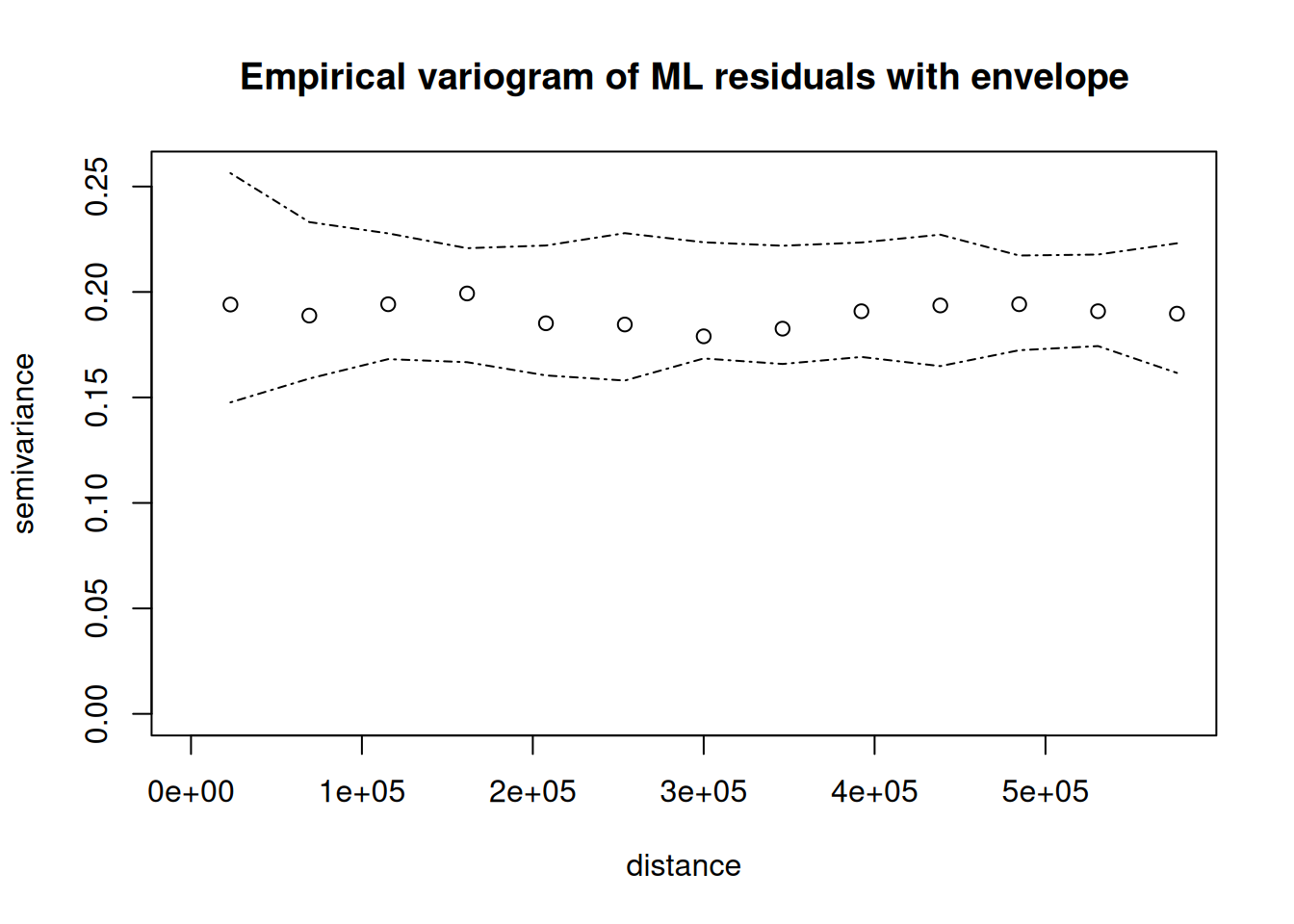
variog.env: generating 1000 simulations by permutating data values
variog.env: computing the empirical variogram for the 1000 simulations
variog.env: computing the envelops
Code
plot(v, envelope.obj=vari.mc, main ="Empirical variogram of ML residuals with envelope")
Fit spatial model to residuals (Gaussian likelihood)
Residuals are approximately continuous, so we use:
inlabru version: 2.13.0.9024
INLA version: 25.12.02
Latent components:
resid_field: main = spde(geometry)
Intercept: main = linear(1)
Observation models:
Model tag: <No tag>
Family: 'gaussian'
Data class: 'sf', 'tbl_df', 'tbl', 'data.frame'
Response class: 'numeric'
Predictor: resid_ml ~ resid_field + Intercept
Additive/Linear/Rowwise: TRUE/TRUE/TRUE
Used components: effect[resid_field, Intercept], latent[]
Time used:
Pre = 1.08, Running = 1.53, Post = 0.154, Total = 2.76
Fixed effects:
mean sd 0.025quant 0.5quant 0.975quant mode kld
Intercept -0.001 0.033 -0.067 -0.001 0.068 -0.001 0
Random effects:
Name Model
resid_field SPDE2 model
Model hyperparameters:
mean sd 0.025quant 0.5quant
Precision for the Gaussian observations 5.33e+00 4.36e-01 4.51e+00 5.32e+00
Range for resid_field 3.21e+05 4.54e+05 2.97e+04 1.87e+05
Stdev for resid_field 8.40e-02 4.40e-02 2.40e-02 7.60e-02
0.975quant mode
Precision for the Gaussian observations 6.22e+00 5.31e+00
Range for resid_field 1.45e+06 7.46e+04
Stdev for resid_field 1.92e-01 5.80e-02
Marginal log-Likelihood: -260.22
is computed
Posterior summaries for the linear predictor and the fitted values are computed
(Posterior marginals needs also 'control.compute=list(return.marginals.predictor=TRUE)')
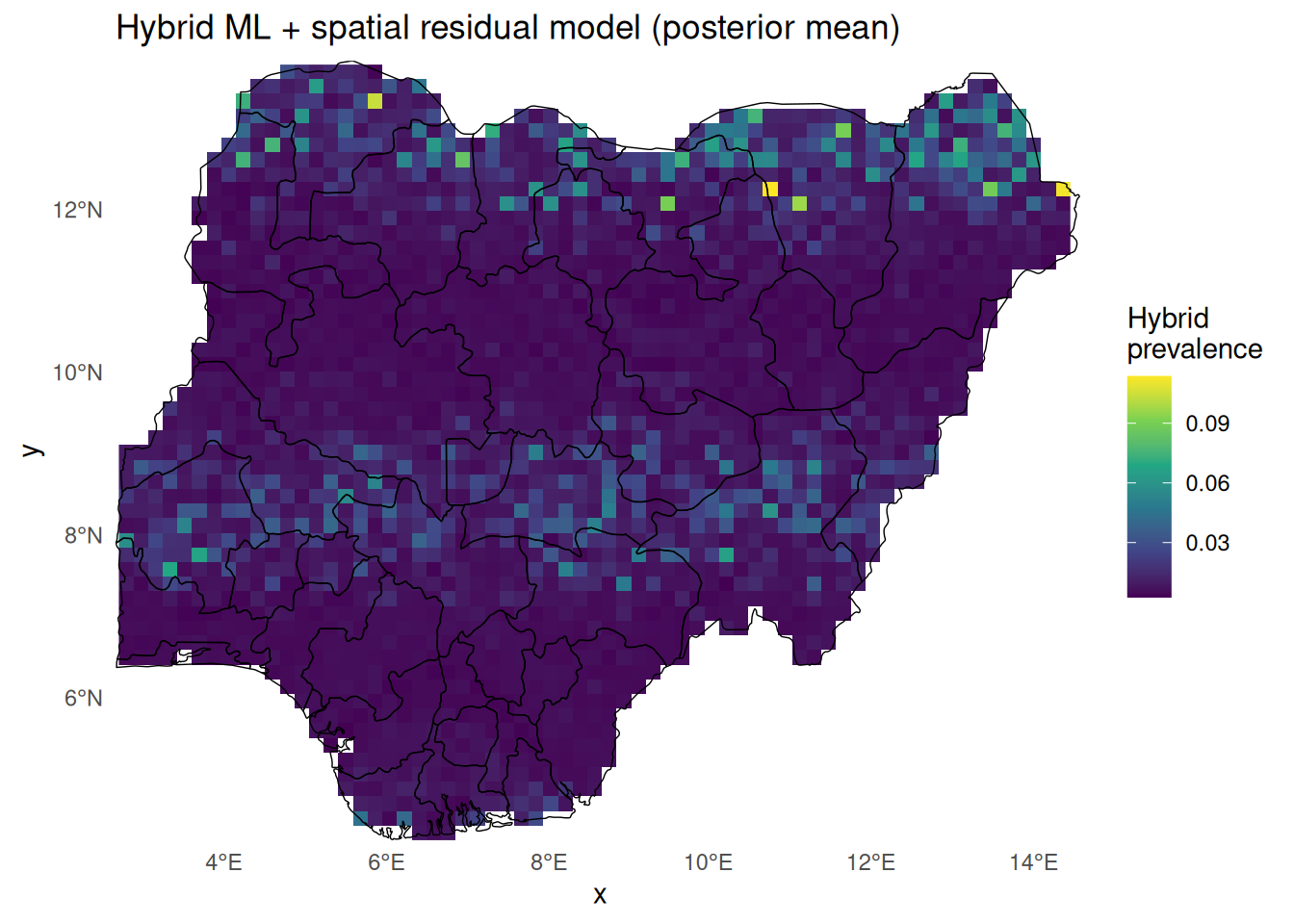
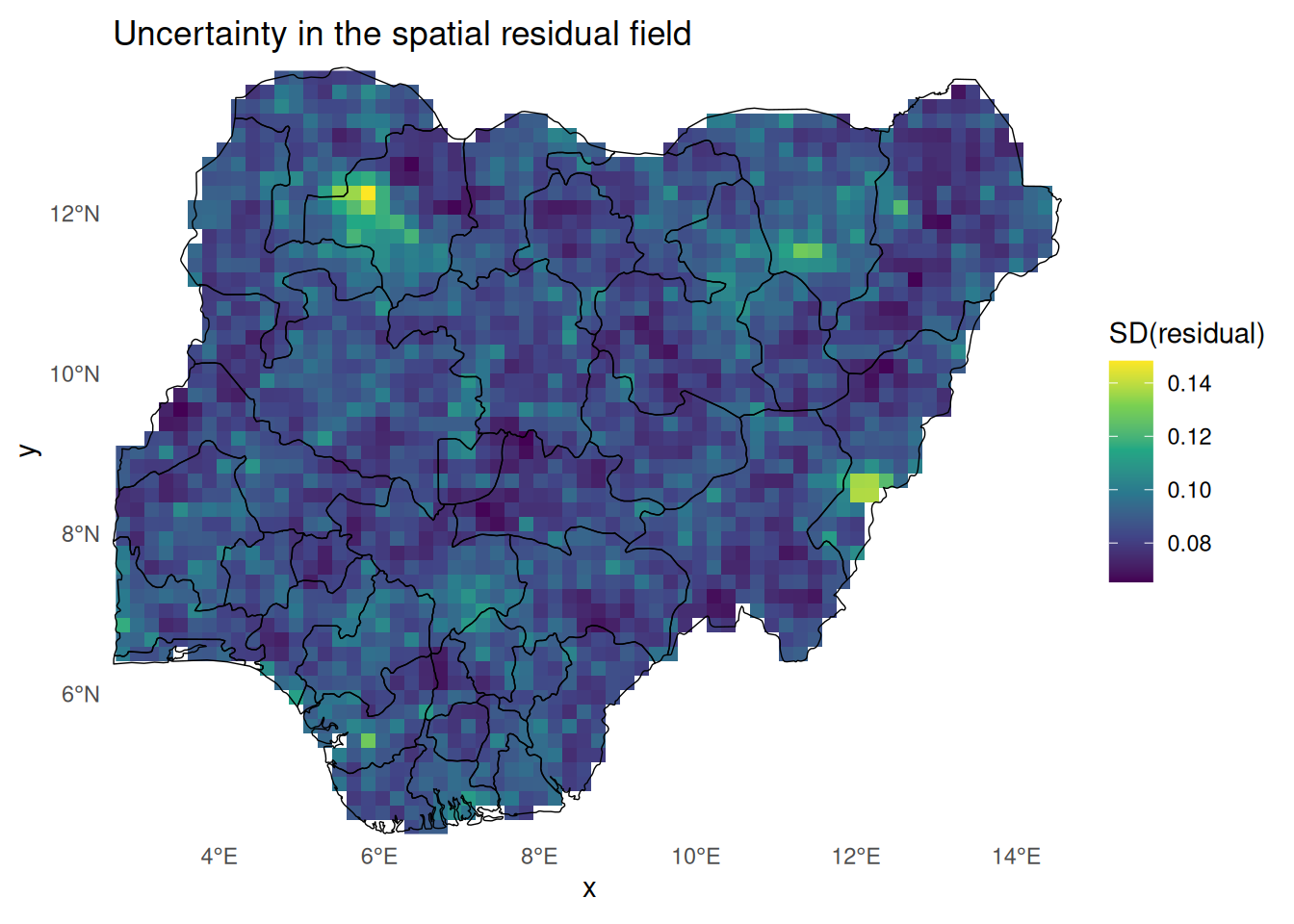
Part 4 — Hybrid predictions: ML + spatial residual surface
Hybrid predictor on logit scale
For any location \(s\):
\[\hat{\eta}_\text{hyb} (s) = \hat{m}(x(s)) + \hat{S}(s)\] Then the prevalence becomes \[\hat{p}_\text{hyb} (s) = \text{logit}^{-1} (\hat{\eta}_\text{hyb} (s))\]
Nigeria boundaries and prediction grid
Code
nga_admin1 <-st_read("data/nga_shapefile.shp")
Reading layer `nga_shapefile' from data source
`/home/olatunji-johnson/Documents/Manchester Job/Teaching/Courses/Nigeria_2026/rcode/FUTA/data/nga_shapefile.shp'
using driver `ESRI Shapefile'
Simple feature collection with 37 features and 121 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -198992.3 ymin: 472813 xmax: 1117766 ymax: 1537228
Projected CRS: WGS 84 / UTM zone 32N